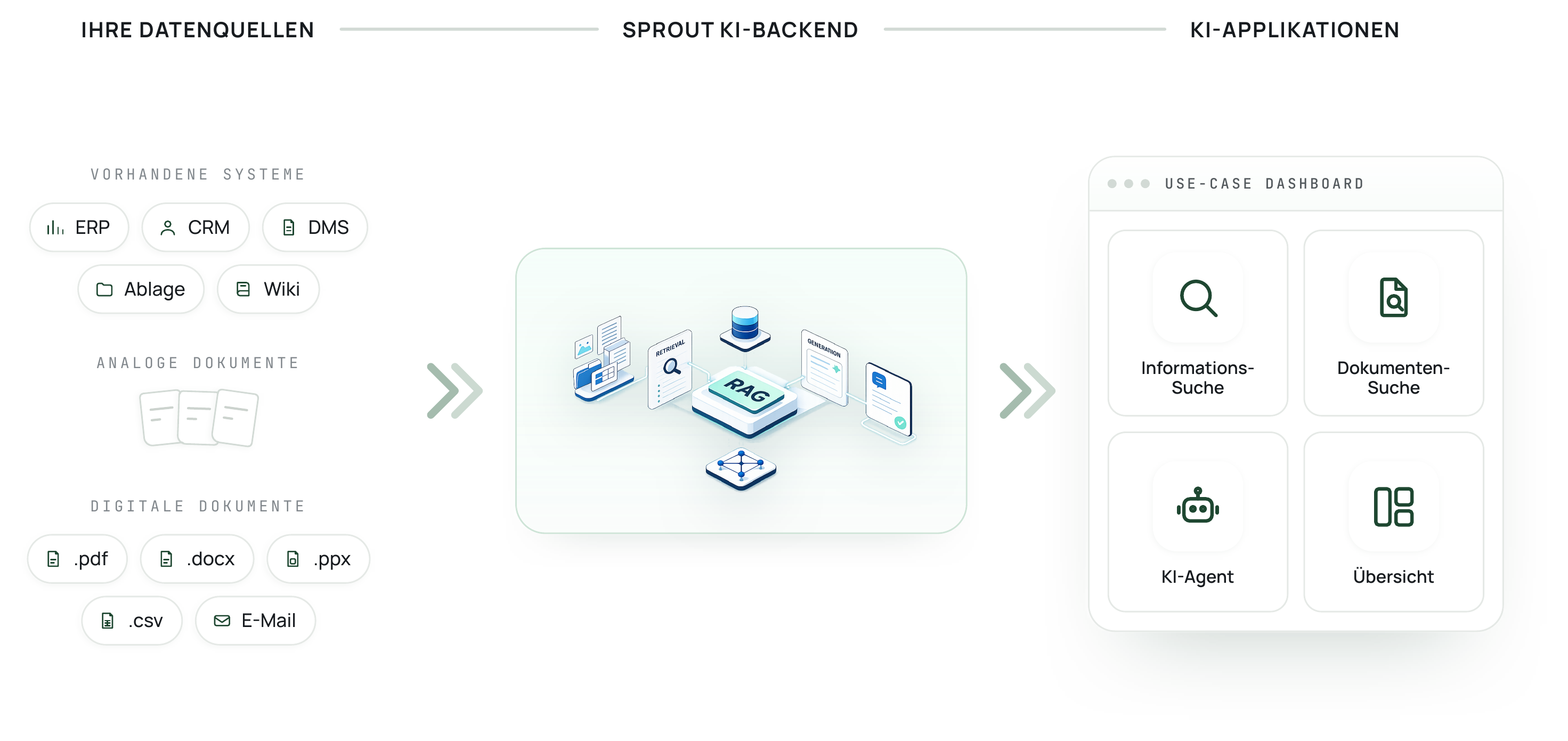
So funktioniert Sprout:
Ein End-to-End-Prozess im Informationsmanagement: Vom Datenanschluss bis zur quellengebundenen Antwort.
KI-Modell
On-Premise / lokale Modelle
Für maximale Datenkontrolle und Betrieb in Ihrer eigenen Infrastruktur.
DSGVO-konforme EU-Cloud
Für skalierbare Modellleistung innerhalb europäischer Anbieter und klarer Datenschutzanforderungen.
Was das System enthält.
Module für den Betrieb. Monitoring für die Kontrolle. Tiefe für Ihren Use-Case.
Dokumenten-Connector
Migration ihrer Legacy-Systeme und Ablagen.
Semantische Suche & RAG-Engine
Retrieval auf Vektor- und Keyword-Ebene.
Chat-Interface
Anpassbar auf Anwendungsfall und Zielgruppe.
Dynamische RAG-Pipeline
Unser System ist entgegen etablierter Lösungen darauf ausgelegt, auch stetig neue Dokumente in die Datenbank zu integrieren.
Die vier Schritte im Detail.
- 01
Ihre Dokumente verbinden
PDF, Word, SharePoint, Confluence, Netzlaufwerk — wir verbinden Ihre bestehenden Quellen in einer abgeschotteten Umgebung. Keine Datenmigration, keine Duplikation.
- 02
Semantische Indexierung
Sprout verarbeitet Ihre Inhalte mit RAG-Architektur (Retrieval-Augmented Generation): Dokumente werden semantisch verstanden, nicht nur per Stichwort durchsucht.
- 03
Fragen stellen — Antworten bekommen
Mitarbeitende nutzen eine saubere Chat-Oberfläche oder eine anwendungsfallspezifische Benutzeroberfläche (z. B. Richtlinien-Assistent, Onboarding-Bot, Vertrags-Recherche). Jede Antwort zeigt die Quelldokumente an.
- 04
Verifikation & Kontrolle
Jede Antwort enthält einen Konfidenzindikator. Bei niedriger Konfidenz wird transparent kommuniziert, dass die Frage außerhalb der Wissensbasis liegt. Kein Erfinden, kein Raten.
Verlässlichkeit als Architektur-Entscheidung. Sprout beantwortet nur, was in Ihren Dokumenten steht. Wenn die Antwort unbekannt ist, sagt das System genau das. Transparenz ist nicht optional — sie ist eingebaut.
Klingt das nach Ihrem Use-Case?
45 Minuten Erstgespräch, kostenfrei. Wir prüfen ehrlich, ob ein KI-Wissensassistent passt.